
PDF craft 可以将 PDF 文件转化为各种其他格式。该项目将专注于扫描书籍的 PDF 文件的处理,目前支持将 PDF 转换为 Markdown 和 EPUB 格式。
它通过逐页读取 PDF,利用 DocLayout-YOLO 和自研算法提取书页中的正文内容,过滤页眉、页脚、脚注、页码等元素。
对于直接扫描生成的中文 PDF 书籍页面,使用 OnnxOCR 进行文字识别,并利用 layoutreader 确定符合人类习惯的阅读顺序。
项目截图
功能介绍
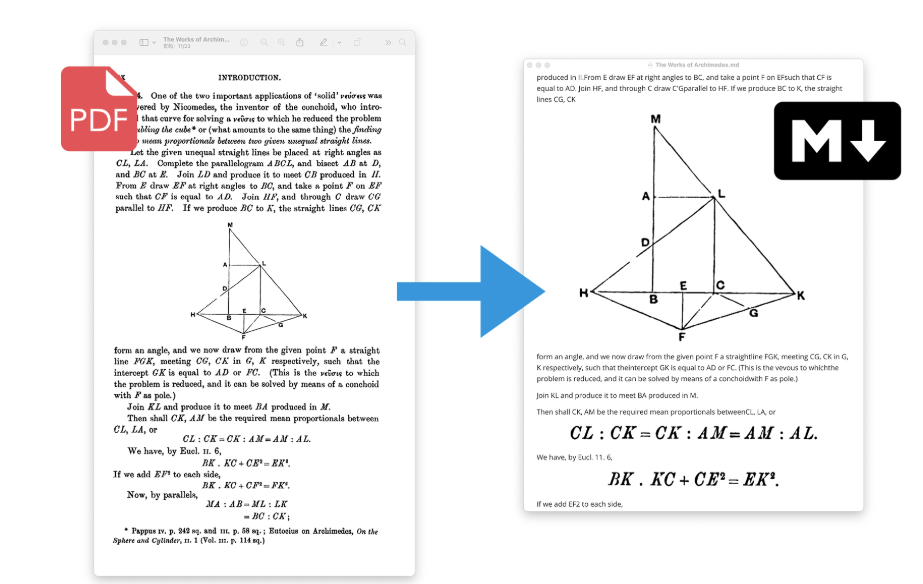
PDF 转化为 MarkDown
此操作无需调用远程的 LLM,仅凭本地算力(CPU 或显卡)就可完成。第一次调用时会联网下载所需的模型。遇到文档中的插图、表格、公式,会直接截图插入到 MarkDown 文件中。
执行完成后,会在指定的地址生成一个 *.md 文件。若原 PDF 中有插图(或表格、公式),则会在 *.md 同级创建一个 assets 文件夹,以保存图片。而 MarkDown 文件中将以相对地址的形式引用 assets 文件夹中的图片。
转化效果如下。

PDF 转化为 EPUB
此操作的前半部分与 PDF 转化 MarkDown(见前章节)相同,将使用 OCR 从 PDF 中扫描并识别文字。因此,也需要先构建 PDFPageExtractor 对象。
之后,需要配置 LLM 对象。建议使用使用 DeepSeek,本库的 Prompt 基于 V3 模型调试。
如上两个对象准备好后,就可以开始扫描并分析 PDF 书籍了。
上述代码注意两个文件夹地址,其一是 output_dir_path,表示扫描和分析的结果(会有多个文件)应该保存在哪个文件夹。该地址应该指向一个空文件夹,若不存在,则会自动创建一个文件夹。
其二是 analysing_dir_path,用来存储分析过程中的中间状态。在扫描和分析成功后,这个文件夹及其内部文件将变得没用(你可以用代码将它们删除)。该地址应该指向一个文件夹,若不存在,则会自动创建一个文件夹。这个文件夹(及其内部文件)可以保存分析进度。若某次分析因为意外而中断,可以通过将 analysing_dir_path 配置到上次被中断而产生的 analysing 文件夹,从而从上次被中断的点恢复并继续分析。特别的,如果你要开始一个全新的任务,请手动删除或清空 analysing_dir_path 文件夹,避免误触发中断恢复功能。
在分析结束后,将 output_dir_path 文件夹地址传给如下代码作为参数,即可最终生成 EPUB 文件。
该步骤会根据之前分析的书本结构,在 EPUB 中分章节,并匹配恰当的目录结构。此外,原本书页底部的注释和引用将以合适的方式呈现在 EPUB 中。


项目链接
地址(中文):https://github.com/oomol-lab/pdf-craft/blob/main/README_zh-CN.md